
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 오름차순 정렬
- lv0
- 프로그래머스 풀이
- 스프링부트 도커
- Queue
- 알고리즘
- java
- 버퍼
- lv2
- SWEA
- 프로그래머스 자바
- 백준 N과 M 자바
- 프로그래머스 문자열 정렬
- 스택
- 자바
- 큐
- Lv1
- 문자열
- 백준
- Programmers
- 스프링부트 도커로 배포
- 스프링부트 도커 배포
- StringTokenizer
- 삼각형의 완성조건
- COS Pro
- index of
- 이진수 변환
- Stack
- 프로그래머스
- 클라이언트
Archives
- Today
- Total
mun dev
[Spring] 스프링 배치(Spring Batch)란? with 예제 본문
스프링 배치(Spring Batch)란?
- 대용량 일괄처리의 편의를 위해 설계된 가볍고 포괄적인 배치 프레임워크입니다.
- 스프링 배치는 로깅/추적, 트랜잭션 관리, 작업처리통계, 작업 재시작, 건너뛰기, 리소스 관리등 대용량 레코드 처리에 필수적인 기능을 제공합니다.
- 최적화 파티셔닝 기술을 통해 대용량 및 고성능 배치 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공합니다.
- 배치가 실패하여 작업을 재시작 하게 된다면 처음부터가 아닌 실패한 지점부터 실행을 합니다.
- 중복 실행을 막기 위해 성공한 이력이 있는 Batch는 동일한 Parameters로 실행 시 Exception이 발생합니다.
일괄 처리가 필요한 경우
- 대용량의 비지니스 데이터를 복잡한 작업으로 처리해야 하는 경우
- 특정한 시점에 스케줄러를 통해 자동화된 작업이 필요한 경우
- 대용량 데이터의 포맷을 변경, 유효성 검사 등의 작업을 트랜잭션 안에서 처리 후 기록해야 하는 경우
배치 애플리케이션이 만족해야할 조건
- 대용량 데이터: 대량의 데이터를 가져오거나, 전달하거나, 계산하는 등의 처리를 할 수 있어야 한다.
- 자동화: 심각한 문제 해결을 제외하고는 사용자 개입없이 실행되어야 한다.
- 견고성: 잘못된 데이터를 충돌/중단 없이 처리할 수 있어야 한다.
- 신뢰성: 무엇이 잘못되었는지 추적할 수 있어야 한다.
- 성능: 지정한 시간안에 처리를 완료하거나 동시에 실행되는 다른 애플리케이션을 방해하지 않도록 수정되어야 한다.
스프링 배치의 3가지 레이어
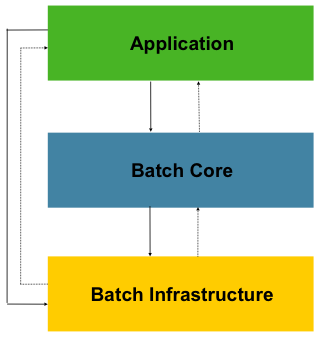
Application: 개발자가 작성한 모든 배치 작업과 사용자 정의 코드포함
Batch Core: 배치 작업을 시작하고 제어하는데 필요한 핵심 런타임 클래스 포함
- JobLauncher, Job, Step
Batch Infrastructure:개발자와 어플리케이션에서 사용하는 일반적인 Reader와 Writer
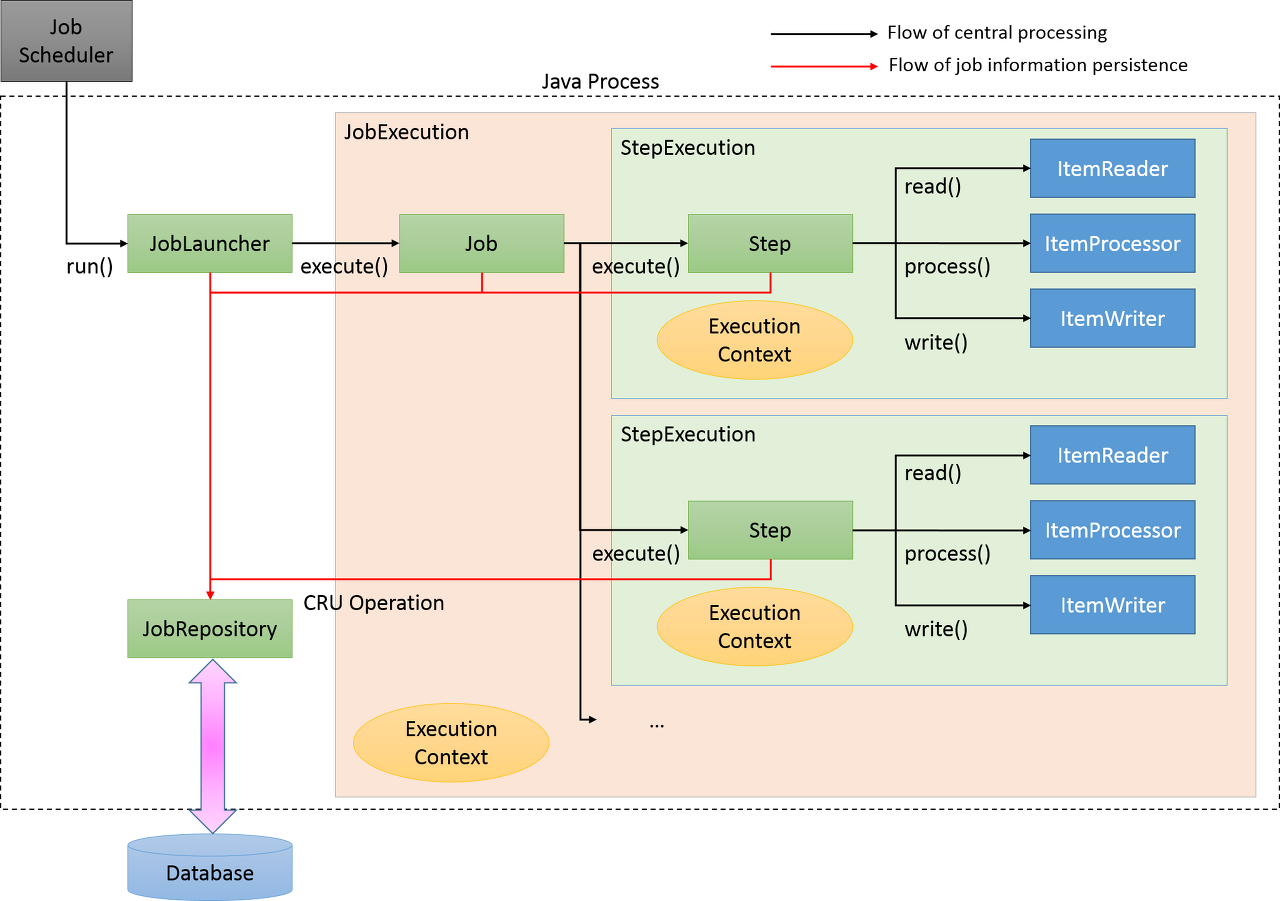
Job
- 배치처리 과정을 하나의 단위로 만들어 놓은
- 배치처리 과정에 있어 전체 계층 최상단에 위치
JobInstance
- Job의 실행단위
- 1번 Job, 2번 Job 실행시 각각의 JobInstance가 생성
- 1번 Job실패시 1번에 대한 데이터만 처리하게 됩니다.
JonParameters
- JobInstance를 구별할 때 사용합니다.
- String, Double, Long, Date 4가지 형식을 지원합니다.
JobExecution
- JobInstance에 대한 실행시도에 대한 객체 입니다.
- 실패하여 재실행 시킨 경우 동일한 JobInstance이나 2번 실행에 대한 JobExecution은 개별로 생기게 됩니다.
- JobInstanced 실행에 대한 상태, 시작시간, 종료시간, 생성시간 등의 정보를 담습니다.
Step
- Job의 배치 처리를 정의하고 순차적인 단계를 캡슐화합니다.
- Job은 최소 1개이상의 Step을 거쳐야 하며 Job의 실제 일괄처리를 제어하는 모든 정보가 들어있습니다.
StepExecution
- Step 실행 시도에 대한 객체입니다.
- 이전 단계의 Step이 실패하면 StepExecution은 생성되지 않습니다.
- 실제시작이 될 때만 생성됩니다.
- StepExecution은 JobExcecution에 저장되는 정보외에 read 수, write 수, commit 수, skip 수 등의 정보들이 저장됩니다.
ExecutionContext
- Job에서 데이터를 공유할 수 있는 데이터 저장소
- SpringBatch에서 제공하는 ExecutionContext는 JobExecution Context, Step Execution Context 2가지 종류가 있으나 이 두가지는 지정되는 범위가 다릅니다.
- JobExecutionContext의 경우 Commit 시점에 저장되는 반면 StepExecutionContext는 실행 사이에 저장이 되게 됩니다.
- ExecutionContext를 통해 Step간 Data 공유가 가능하며 Job실패시 ExecutionContext를 통한 마지막 실행 값을 재구성할 수 있습니다.
JobRepository
- 위의 모든 배치처리 정보를 담고 있는 매커니즘
- Job이 실행되게 되면 JobRepository에 JobExecution과 StepExecution을 생성하게 되며 JobRepository에서 Execution정보들을 저장하고 조회하며 사용하게 됩니다.
JobLauncher
- JobLauncher는 JobParameters를 사용하여 Job을 실행하는 객체입니다.
ItemReader
- Step에서 Item을 읽어오는 인터페이스
- ItemReader에 대한 다양한 인터페이스가 존재하며 다양한 방법으로 Item을 읽어올 수 있습니다.
ItemWriter
- 처리된 Data를 Writer할 때 사용합니다.
- 처리 결과물에 따라 Insert, Update, Queue의 Send등이 될 수 있습니다.
- 기본적으로 Item을 Chunk로 묶어 처리하고 있습니다.
ItemProcessor
- Reader에서 읽어온 Item을 데이터 처리하는 역할을 합니다.
- Processor는 배치를처리하는데 필수요소는 아니며 Reader, Writer, Processor처리를 분리하여 각각의 역할을 명확하게 구분합니다.
스프링 배치 사용 예제
1. SpringBatch Dependenciy 추가
implementation 'org.springframework.boot:spring-boot-starter-batch'
2. SimpleJobConfig 생성
@Slf4j
@Configuration
public class SimpleJobConfig {
@Bean // 기본 싱글톤 : 스프링부트 앱이 꺼지기 전까지 살아있음
public Job simpleJob(JobRepository jobRepository, Step simpleStep1, Step simpleStep2){
return new JobBuilder("simpleJob",jobRepository)
// 파라미터가 다르면 새 명령으로 보기 때문에 밑에 추가한 내용을 잠시 주석 처리
// .incrementer(new RunIdIncrementer())// 강제로 매번 다른 ID를 실행시에 파라미터로 구현
.start(simpleStep1)
.next(simpleStep2) // 위에꺼 다 실행된 후에 실행
.build();
}
@Bean
@JobScope // 독립적으로 실행하기 위헤 Scope 추가
public Step simpleStep1(JobRepository jobRepository, Tasklet testStep1Tasklet, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("simpleStep1",jobRepository)
.tasklet(testStep1Tasklet,platformTransactionManager).build();
}
@Bean
@StepScope
public Tasklet testStep1Tasklet(){
return ((contribution, chunkContext) -> {
System.out.println(">>step1");
return RepeatStatus.FINISHED;
});
}
@Bean
@JobScope
public Step simpleStep2(JobRepository jobRepository, Tasklet testStep2Tasklet, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("simpleStep2",jobRepository)
.tasklet(testStep2Tasklet,platformTransactionManager).build();
}
@Bean
@StepScope
public Tasklet testStep2Tasklet(){
return ((contribution, chunkContext) -> {
System.out.println(">>step2");
/*
if(true) { // 두번째 스텝이 실패하도록 => 성공하도록(위에 주석처리 후 false로 실행하면 실행 실패한 step2만 다시 실행)
throw new Exception("Fail: step2");
}
*/
return RepeatStatus.FINISHED;
});
}
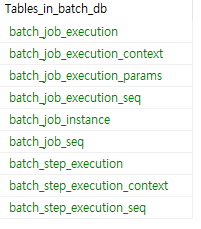
}이런식으로 하나의 잡에 2개의 스텝을 생성하여 테스트를 하였으며,
코드를 실행하게 되면 밑에와 같이 메타 테이블이 자동으로 생성되는 것을 볼 수 있다.
'공부 > Spring' 카테고리의 다른 글
| [Spring] @ManyToMany 다대다연관관계 (0) | 2023.11.04 |
|---|---|
| [Spring] 공공데이터 API 데이터 DB에 저장하기 (0) | 2023.09.28 |
| [Spring] 민감정보 숨기기 Argument 입력 (0) | 2023.05.18 |
| [Spring] JPA란? (0) | 2023.03.19 |
| [Spring] 스프링부트 마리아DB 연동 (0) | 2023.03.17 |
'공부/Spring' Related Articles
more


